
Die Studierenden des Studiengangs Digital Business Management konnten das Wahlmodul Data Science & Machine Learning besuchen und in die Welt der datengetriebenen Analyse eintauchen.
Mein Name ist Elia Perenzin und ich studiere Digital Business Management. Ich hatte das Vergnügen das Wahlmodul Data Science & Machine Learning bei Ingmar Baetge zu besuchen. Im Modul erhielten wir einen breiten Einblick in die Techniken, welche für das maschinelle Lernen verwendet werden. Die Themen reichten von "supervised learning", "unsupervised learning" bis hin zu "reinforcement learning" mit neuronalen Netzen. Da die Welt des maschinellen Lernens sehr komplex und zu umfangreich für einen Kurs über sechs Tage ist, erhielten wir nur einen oberflächlichen Einblick in die einzelnen Themen. Ebenfalls wurde ein eigenes Semesterprojekt durchgeführt, welches ich hier in diesem Blogbeitrag vorstellen möchte.
Die Aufgabe
Der Auftrag für das Semesterprojekt war sehr offengehalten. In Teams von zwei bis drei Personen sollte ein kleines Data-Science-Projekt durchgeführt werden. Dazu konnten eigenständig Daten gesucht und analysiert werden. Das Ziel war es anhand der Daten ein passendes Modell zu trainieren. Das Projekt führte ich mit Jessica Nigg und Dominic Kunz durch.
Die Daten
Für das Projekt wählten wir keinen Standartdatensatz aus dem Internet, denn wir wollten nicht etwas analysieren, was bereits zuvor in unzähligen Tutorials behandelt wurde. Wir entschieden uns, einen eigenen Datensatz zu verwenden. Ein Skript, welches auf einem Raspberry-Pi läuft, sammelte während dem Zeitraum von 11 Monaten alle 5 Minuten die freien Parkplätze von allen Parkhäusern in Zürich. Die Idee für das Skript entstand in einem früheren Semester an der Fachhochschule und sammelte seither die Daten. Der Datensatz enthielt über drei Millionen Datenpunkte, welche sich perfekt für dieses Projekt eigneten.
Die Features
Im originalen Datensatz war nur ein Zeitstempel vorhanden. Zu Beginn mussten wir deshalb weitere Felder (Features) berechnen, um ein gutes Modell zu trainieren. Die Features, welche aus dem Zeitstempel berechnet wurden, waren zum Beispiel der Monat, Wochentag, Stunde und Tageszeit.
Die Analyse
Aus den Daten wurde eine Grafik generiert, damit wurde versucht zu erkennen, ob überhaupt eine Regelmässigkeit in den Daten vorhanden ist. Zusätzlich wollten wir überprüfen, ob die Auswirkungen der Jahreszeiten oder der Einfluss der Corona-Pandemie in den Daten ersichtlich sind. So konnten Parkhäuser identifiziert werden, bei denen es Sinn macht, ein Modell zu trainieren, weil sie eine gewisse Regelmässigkeit aufzeigen.
Im Diagramm "Feldegg" kann man gut die Regelmässigkeit in den Daten erkennen. Das Parkhaus ist jeweils in der Nacht und am Morgen nicht stark ausgelastet. Am Tag steigt die Auslastung (durch die dunkel schattierten Felder zu erkennen). Im Beispiel "Accu" ist keine solche Regelmässigkeit erkennbar, deshalb eignet sich dieses Parkhaus nicht um ein Modell zu trainieren.
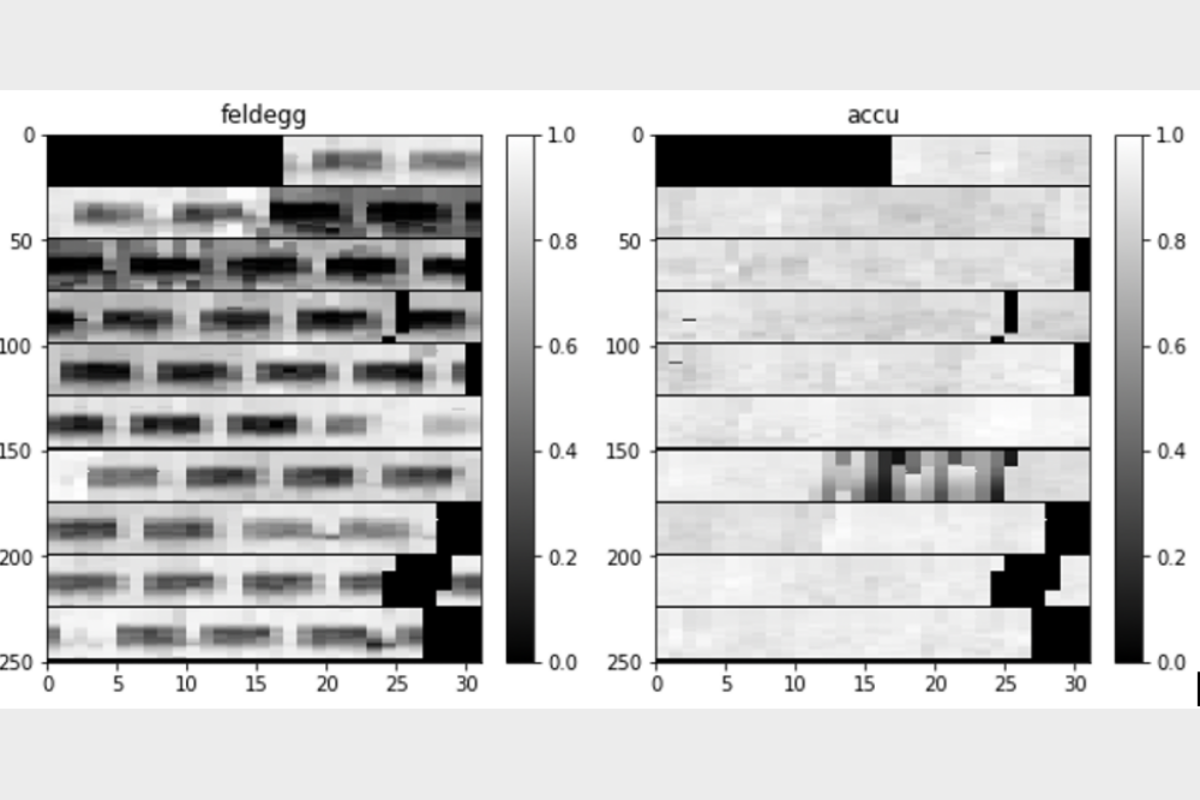
In dieser Grafik sieht man die durchschnittliche Auslastung eines Parkhauses pro Stunde anhand der Schattierung. In einer Zeile sind die Monate abgebildet. Die Spalten repräsentieren die Tage im Monat, die einzelnen Pixel repräsentieren jeweils den durchschnittlichen Wert innerhalb einer Stunde. Ein dunkler Pixel bedeutet dabei eine hohe Auslastung, ein heller Pixel eine niedrige Auslastung des Parkhauses.
Das Model
Das Trainieren eines guten Modelles war die grösste Herausforderung des Projektes. Zusätzlich sollte nicht nur ein Modell trainiert werden, sondern für jedes Parkhaus der Stadt ein individuell angepasstes Modell. Um Erfahrungen zu sammeln, trainierten wir eine Reihe verschiedener Modelle mit Hilfe verschiedener Lernalgorithmen. Zunächst experimentierten wir mit einer linearen Regression, aber es wurde schnell festgestellt, dass ein solches Modell nicht erfolgreich sein kann, da die Daten keine rein lineare Abhängigkeit zueinander haben. In weiteren Experimenten probierten wir das "decision tree"-Modell und landeten dann schlussendlich beim "random forest"-Modell.
Die Modelle, welche mit einem "random forest" trainiert wurden, zeigten eine sehr hohe Performance. Scores von über 90 % waren keine Seltenheit und wir waren begeistert von den Resultaten. Doch leider trübten die ersten Resultate und wir mussten feststellen, dass wir es mit einem klassischen "overfitting" zu tun hatten. Die Trainings- und Testdaten waren nicht sinnvoll aufgeteilt. Wir arbeiteten mit einem klassischen 80-20-Split. Was bedeutet, dass 80 Prozent der Daten für das Training und die anderen 20 Prozent für die Validierung verwendet werden. Da dieser Split zufällig generiert wird, hatte das Modell zum Beispiel einen Datenpunkt für den 28. Januar 2021 um 8:00 Uhr und als versucht wurde, eine Vorhersage für den 28. Januar 2021 um 8:05 Uhr zu machen, hatte das Modell leichtes Spiel da der Datenpunkt bis auf 5 Minuten bereits bekannt war.
So mussten die Daten mit einer anderen Technik aufgeteilt werden, wir versuchten es mit dem "K-Fold". "K-Fold" liefert Train/Test-Indizes, um die Daten in Train- und Test-Sets aufzuteilen. Es teilt den Datensatz in k aufeinanderfolgende Folds auf. Die Folds waren in unserem Fall die 10 Monate des Datensatzes. Mit diesen 10 Folds wurden 10 verschiedene Modelle trainiert, dabei wurde das Modell jeweils mit einem anderen Monat validiert. Mit dieser Variante erreichten wir realistischere Werte für unser Modell.
Fazit
Das ganze Projekt war für uns eine Achterbahnfahrt, mit vielen vermeintlichen Erfolgen und einigen harten Rückschlägen. Zum Schluss konnten wir als Team ein Modell trainieren, welches gute Resultate produziert und gleichzeitig auch für verschiedene Zeiträume generalisiert. Wir konnten sehr viel lernen durch das praktische Anwenden des gelernten Unterrichtsstoffes und durch den regelmässigen Austausch mit dem Dozenten konnte individuell auf Probleme im Projekt eingegangen werde.
Der ganze Sourcecode ist öffentlich auf GitHub ersichtlich.